
Much has been written about the Google Panda algorithm, and other quality and core algorithm updates such as Phantom or RankBrain.

Images courtesy Ed Schipul, Allan Ajifo, and Will Sowards on Flickr.
Have these algo changes affected your site’s rankings? I guarantee it…even if you didn’t see a boost or a push-down in the rankings, you can be sure that some of your competitors got hit and lost rankings, and probably some of them got a boost as well. What makes it tough on webmasters and SEO people is that while we know vaguely the kinds of things Google is looking at when it comes to site quality, Google is thin on delivering specifics of what they’re targeting, and even thinner on specific technical advice–presumably to avoid giving the black-hat SEOs too much information.
Google’s Goals on Quality
Panda was created originally back in February of 2011, with the idea being to analyze the content on a web page, scoring the page on how great the content was, and how great the user experience was. Prior to Panda, on-page analysis by Google seemed to be mostly scanning the HTML elements like the page title, headings, body text, ALT text on images, etc. to see what terms it found related to the search term in question. Panda brought the ability to render a page much like a browser would, and analyze the layout of the content, see what percentage of a page was actual page content vs. navigation, template elements, and ads. Panda also brought the ability to look at a site’s quality overall–and if your site seems to be mostly really thin pages that are mostly template and little content, or duplicates of each other, or mostly syndicated content from other sites, then sending a user to even one of the great pages on your site could be a bad user experience, since most of the other pages they might click to after that page really suck.
Phantom, version 3 of which hit on November 19th, 2015, appears to target (and punish) pages that are really just indexes or catalogs of content, like blog category or tag archive pages. Marcus Tober of SearchMetrics dives into this in more detail here. The general idea is that if a user is looking for a page all about purple widgets, then a page that’s just a list of snippets and links to other pages about purple widgets isn’t nearly as good a result for the user as a page that’s had content written specifically to explain all about purple widgets, so they want to push those category/tag archive pages down in the results and let the custom, dedicated type pages bubble up in the rankings.
RankBrain was announced in October 2015, despite apparently being integrated into core algorithm sometime in the spring of that year. This part of the algorithm is now apparently the 3rd most important signal in terms of relevance, according to Greg Corrado, a Google senior research scientist.
RankBrain appears to be able to score a page for relevance for a given topic (notice I didn’t say “search term”) based on co-occurrence of other topics or sub-topics. It’s theorized by some (and I’d agree) that they’re doing this by measuring the occurrence of relatively unusual phrases on other pages about that topic on the web. The idea is this: let’s say the topic is “tahiti weather”. RankBrain might look at the top 100 pages or so (according to their other relevance algo scores), and perhaps finds “humidity” on 95% of those pages; finds “cyclones” on 40% of those pages; finds “surfing conditions” on 10% of those pages. So, if YOUR page doesn’t have “humidity” on it, it’s probably not really about Tahiti weather; if you’ve got “cyclones” on the page, then you’re covering the basics; if you’ve got “surfing conditions” on your page, then your page is likely to be one of the most thorough pieces of content on that topic.
Last but certainly not least, it’s critical to understand that by and large, Google deals with single pages. The search results consist of links to single pages, not groups of pages. Yes, overall site quality, and overall domain authority contribute to ranking. But if Google is looking for the perfect page about purple widgets, and you’ve split your content across 10 pages, Google is going to pick ONE of those ten pages, and its content is going to have to try to stand and compete–with ONLY its content, forgetting about the other 9 pages–against your competitor, who’s got all their juicy content packed into one page.
The Algo Update Process
Image courtesy x6e38 on Flickr.
Google’s got some smart engineers, for sure–but they’re not demi-gods. They’re regular software developers…imperfect humans, with schedules, deadlines, vacations, and likely a great fear of being responsible for an algo change mistake that gets them in the news.
As they work on a new piece of the algorithm, here’s what they’re probably going to do:
- target a particular quality measurement
- write a new piece of the algorithm that analyzes a page and comes up with a score
- take what they hope is a representative sample of different kinds of web pages to test the algorithm against
- compare the scores that it comes up with against what a human would feel about those pages
- refine and adjust the amount of impact to try and strike a balance between improved search results for the vast majority of searches, and false positives/negatives because of unusual HTML or implementations that fool the algo
Google also has process to consider: things like integrating Panda into the main algorithm, integrating various organic search algorithm pieces into local search, bug fixes, and adapting the new pieces of the algorithm where there are large numbers of false positives/negatives.
What is Google Likely to be Trying to Mechanically Measure

Image courtesy Bill Brooks on Flickr.
At a very high level, it’s:
- layout
- originality
- quality of writing
- breadth and depth of coverage of topic
- user experience
- user experience on the site after visiting the landing page.
Too Cool For School
As webmasters and designers push the envelope, developing new kinds of user experience, they run the risk of creating something that runs afoul of the quality scoring pieces of Google’s algorithms. Content that Googlebot can’t see, such as content loaded by Javascript/Ajax on a delay, or on a user action like a scroll of the page or the click of a Next Image button. Pages that are beautiful, simple, light, and airy….but make the user scroll to find the information they came looking for. Gorgeous, big images that are implemented as background images in CSS (is it just decoration? Wallpaper? Or real content?), or using experimental new HTML such as <picture>.
Luckily, it’s easy to see if Google can see the content at all–just go to Google Search Console (aka Webmaster Tools), and do a Fetch and Render as Googlebot. You’ll see a snapshot of what Googlebot is PROBABLY seeing on your page. I say “probably” because the tool is notorious for timing out on fetching page elements like images, stylesheets, etc., and I’d guess that the actual rendering engine they use to measure the content is more forgiving. But maybe I’m wrong…
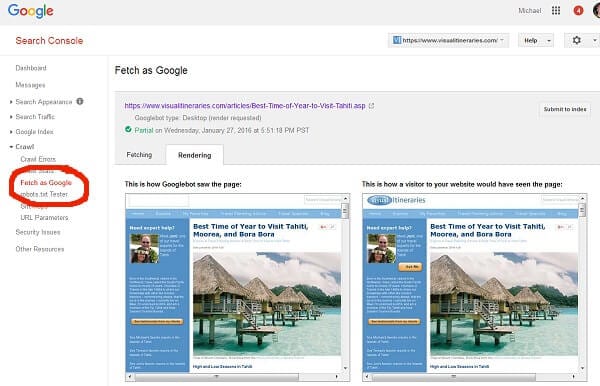
What we can’t see is Google’s interpretation of a given piece of content. Is it looking at that medium-sized image that’s linked to another page as content? Or as a navigational button? Is it seeing your lovely product image slider as content about the product? Or because it’s a background-url in CSS, does Google think it’s just decoration, and the only content is the 3 words superimposed over the image?
The most beautiful, modern, stylish, slick user-experience website in the world is worthless if no customers come to visit it. If your implementation makes the content invisible to Google, or makes Google misinterpret what the content elements are, then you might be kissing organic search traffic goodbye.
It’s All a Bet
Do we know whether Google Panda is counting images that are linked to other pages as relevant content on the page, or presuming it’s just a navigational element–a button. We don’t. In the case of image carousels and sliders, so many are implemented as background-url in CSS, it’s likely that Panda is going to see those as content.
For the business owner, that’s a scary bet. Imagine if your boss came up to you and said there was a 70% chance you’d get a paycheck next week. That’s the risk you’re running for the website owner if you’re taking chances on how Google is seeing your content.
Best Practices
Googlers like Matt Cutts are fond of telling us to do the right thing for the user experience, and it’ll all be rainbows and unicorns.
By and large, this is really good advice. Hand-write a 3000 word, really thorough, well-written discussion of a topic, with original images/illustrations, embed a video, show where it is on an interactive map–this kind of content is going to generally score well in Google’s various quality algorithms.
But it can pay to take a technical approach to the content as well–looking to see how Google is likely to perceive each piece of content on the page (content? background? navigation?), make sure Googlebot renders it properly (Search Console -> Fetch as Google).
Does your fabulous “everything about purple widgets” page actually look a lot like a category archive page? (I have a client with this problem right now….big traffic drop on November 19th).

Are you splitting content about a topic across multiple pages, to make the pages load fast? But perhaps now, Google is seeing 10 pages–each of which barely cover any of the topic. Consider combining those pages into 1 using a tabbed approach…and, if there are some parts of the content that make the page load too slowly this way, you can lazy-load a select few of those bits of content.
Does your user experience result in a ton of really thin pages for functions like Add to Cart, Add to Wishlist, Email to a Friend, Leave a Review? You can keep your UX as-is….just make sure you set your meta robots to “noindex,follow” on those pages, so you’re not telling Google you think those pages are rockin’ hot content that should be indexed. You want Google to look at the set of pages you’re pushing at them to be indexed (via your XML sitemap AND the meta robots on every page–don’t forget to make sure these are consistent), and have Google’s quality score average for all those pages be really nice and high.
And, for RankBrain, you’re well advised to do the search for the target term for your page, and read the pages that come up in the top 20-30 results. Are they discussing sub topics or related topics that you’ve totally left out? Are they using synonyms that you aren’t–and maybe you could replace 1 of the 3 references to a given term with the synonym?
Another place to look is Google Search Console, in Search Analytics. As of last summer, you can now see all the terms for which you’re appearing in the first few pages of the results, along with clicks, impressions, and rankings–on a per-term, per-page basis. Look here for terms that you’re ranking badly for, get a fair number of impressions, and you don’t have that term on the page today.
Wrapping Up
You don’t have to forgo beautiful design and great UX in order to please the Google ranking algorithms–but it’s worth your while to also take a technical look at your site, with Googlebot, Panda, RankBrain, and Phantom in mind.
And don’t worry too much about what Google can and cannot measure today–in the immortal words of Canadian hockey legend Wayne Gretzky (whose birthday was yesterday): “I skate to where the puck is going to be, not to where it has been.”

Photo courtesy waynegretzky.com.
SEO consultant, specializing in organic search, site audits, Panda optimization, and penalty recovery. Founder of Visual Itineraries travel planning website.
Thanks for sharing Michael! For now, RankBrain has only a small impact on the results. However, in time, this effect will most likely increase. If RankBrain goes full out, encompassing 100 % of results, do you think that this will render website stats irrelevant?
Actually, RankBrain affects all results today. See this story from SearchEngineLand from last week:
https://searchengineland.com/google-loves-rankbrain-uses-for-every-search-252526
But it’s still only one of the ranking factors in the algorithm.
Oh, I will have to read this one. Thanks for the link!