
I spend a lot of my day doing technical site audits for clients. It’s often pretty tedious work, but I’ve run into a number of little problems–things that often aren’t even visible to the user–that had giant repercussions for search. There have been a few of them where the fix was BIG…where the development team explained how everything depended on X, and changing X would take forever and break everything and the site would be ugly and users would cry…etc. Then we’d have the little conversation that goes “Well, then, how ARE you going get your customers…since you won’t be getting any from Google!”
Without further ado, here are some of the biggies I’ve run into.

Photo courtesy Robert Huffstutter on Flickr.
Staging servers getting indexed
It’s pretty common to have a staging environment where you can put the latest version of your website for testing and review before going “live” with it. And if your team is in multiple locations, then the easy thing to do is just put it out there on the internet…maybe on a subdomain, like staging.mywebsite.com. The problem comes when somehow, somewhere, Google discovers the site (perhaps you sent a link to it using your Gmail account?). And indexes it.
Now what happens when you move the new version of the site to the live site. What does Google see? Clearly you’re a scraper–Google’s seen all that content weeks ago (and still sees it). Your live site looks like just a copy of the staging site, which appears to Google to be the original (saw all the content there first, after all).
But it’s not super obvious what’s happened–because the staging site has virtually no links to it, it doesn’t rank. But your live site, with all its links, is seen by Google as a festering pile of duplicate content.
The solution? Block all user agents in the robots.txt file on the staging server using Disallow: /.
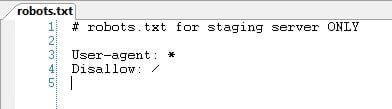
Oh, and when you go to move the pages from the staging server to the live site? You’re not going to want to move that robots.txt file too 🙂 Think about it….
Ajax and Content
Ajax is awesome for site performance, user experience, etc. But be careful how you use it to populate your page with content. Google will call Javascript functions to render content, sure–but typically only what’s in the onload() function. If your page requires another event in order for the Ajax to be called (like a page scroll down, for example), don’t count on Google executing THAT. Your lovely content-rich, Panda-happiness-making 3000-word 10-big-photo page that loads only 1 photo and the first 3 sentences before scrolling…well, Panda is only going to see that first part.
The Site of Many Flavors
So your site responds to requests for mysite.com as well as www.mysite.com? And, you jumped on the bandwagon and made it work under https when Google announced that https pages would get a ranking boost (yeah, right :-/)? Fabulous. But did you do your redirects? If you DON’T 301 redirect from your non-www to your www version (or the other way around is ok too), and you DON’T 301 redirect requests for https to https, then Google will see 4 complete, separate websites…all with the same content.
Just updating your menus to link to everything with www and https isn’t enough. Google’s still got a memory of those non-www and non-https pages (probably from other sites that linked to you a while ago).
Side note here: when you DO move to https, make sure you create a new project in Google Webmaster Tools for the https site. You’ll find that only some of the stuff will still show up under your old https project there.
Robots.txt blocking style sheets
With the avalanche of hackers out there ripping into WordPress sites, people are doing all sorts of things in a desperate attempt to keep the wolves at bay. And so they block wp-content, wp-includes, and wp-admin in their robots.txt file.
But, first of all, only spiders respect robots.txt…hackers giggle at your lame attempt to block them, and go right on in.
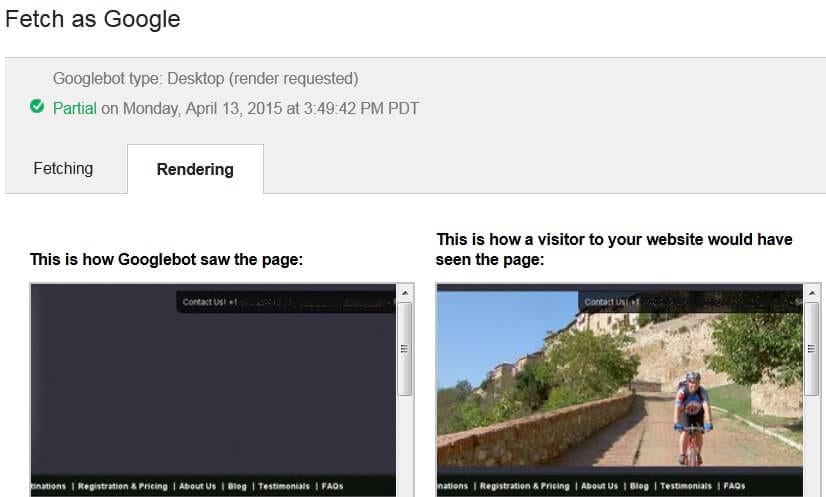
The problem that is caused by blocking these is that you may have style sheets in those folders that are needed to render images, menus, etc. When Google Panda goes to take a peek at your page and see all your lovely content–especially that content above-the-fold–if the stylesheet is blocked by robots.txt, there might be nothing for Panda to see. You can see how Google sees your page by doing a Fetch & Render in Google Webmaster Tools. I’ve had clients whose sites have been totally image-free because of a blocked style sheet; multiple clients have had what should have been a horizontal menu with pulldowns turn into a vertical 3-page list of black menu items on a white background. Oops.
Blocking in robots.txt instead of doing a noindex,follow
There’s really very few reasons to EVER block anything in robots.txt. One good exception is the staging site example from above. But besides that, it’s NOT the best way to shape what Google indexes on your site, and here’s why.
When you block a set of pages in robots.txt, you’re telling Googlebot STAY OUT. The pages won’t be crawled, and the links on them to other pages on your site won’t be counted.
What you ACTUALLY want to do is to set meta robots directives in the pages themselves like this:
<meta name="robots" content="noindex,follow" />
This tells Google to go ahead and crawl the page, and count the link juice outbound from that page to other pages, but don’t bother indexing the page.
Let’s say you have a “share this page” link on all pages of your 10,000 page site. And that sharing page of course has really nothing on it, so you don’t want it indexed. But, that sharing page has the main navigation on it, like any other page, with links to your 300 most important pages.
Blocking /share-page.html in robots.txt means all the link juice of the 10,000 different share-page.html pages (because you’re probably passing the page to be shared as a parameter, e.g. share-page.html?page=purple-widgets.html) that WOULD have gone to your 300 most important pages is flushed down the toilet. If, instead, you did a noindex,follow on those pages, then you’d have 10,000 more little bits of link juice flowing to those 300 most important pages.
Joomla’s Big Bad Default Setting
Joomla, by default, disallows the /images/ folder. So Google sees no images on ANY of your pages. Pretty dry, boring site you’ve got there, dude.
.htaccess is NOT your firewall
Back to them evil hackers. Yes, they’re out there, and yes, there’s a TON of them. The SEMpdx blog has probably had a few hundred hacking attempts in just the time I’ve spent writing this blog post.
Did you know you can block IP addresses in .htaccess? And did you know that lists of IP addresses for China, Russia, Nigeria, etc. are out there?
Don’t do it. You’re using a hammer to drive in a screw.
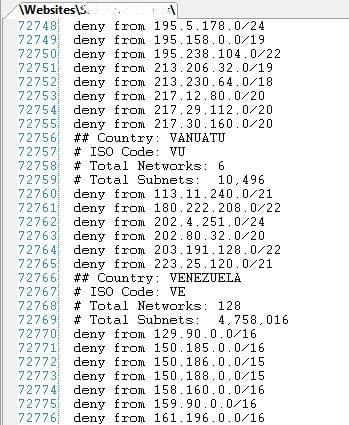
I had a client who had blocked some IP addresses in his .htaccess file. By “some” I mean over 73,000 lines of this in his .htaccess (see below…this is his actual file, and them are real, live line numbers!). Now, the .htaccess file gets read and parsed for every https request made. Which means that on a page with 3 style sheets, 20 images, and 7 Javascript files included, the .htaccess file got read and parsed 30 times. A relatively lightweight site was seeing page load times of over 20 seconds. Ouch.
To hell with URL standards
Don’t stifle my creative side, man. I’ve got a new smooth way to use characters in URLs. Y’all are gonna love it.
I had a client who was using # characters instead of ? and & for parameter separators. They couldn’t figure out why Google only indexed their home page, when they had hundreds of thousands of pages of content.
The # character is supposed to be used to indicate an in-page anchor. Everything AFTER that isn’t technically part of the URL; it’s a location within the page.
A/B Testing Gone Wild
My client was using regular parameters in the URL for A/B testing mods to their home page, e.g.:
- https://www.mysite.com/?version=A
- https://www.mysite.com/?version=B
That’s not NECESSARILY a bad idea–you can use rel=canonical to point both of those to the base page, https://www.mysite.com/, and you should be OK. But if you neglect to do that, all of a sudden you have 3 different home pages, in Google’s eyes anyway.
Here’s a case where using the # for something other than an inpage anchor wouldn’t have been such a bad idea.
404 to the home page
If you thought an easy way to handle not-found pages (and capture otherwise lost link juice) would be to set up your 404 handler to 301 redirect to the home page, you’d be right. It IS an easy way. But like a lot of easy things, it’ll bite you.
Google wants to see an HTTP 404 error code returned when a non-existent page is fetched. My theory is that it’s because some spammy people at one time figured they could make Google think they had a million-page site by creating links to URLs to a million pages, then fabricate content on-the-fly in their 404 handler by taking the words out of the URLs and injecting them into a template of other words. Then, if that template had a link to somewheres else on it, well then, some little page might be gettin’ a heap of link juice, might’n it.
Doesn’t matter if I’m right about this, or if I did it myself at one point. I mean, if I had THIS FRIEND who did that at one point. What matters is that Google will check your site for this every few weeks. Look in your webserver logs long enough, and you’ll see Googlebot trying to fetch a URL that’s really long, a big jumble of letters and numbers.
Not only does Google check in this fashion, but if Google finds there’s pages on your site that come back nearly empty and SEEM to be page-not-found pages, Google will mark those as “soft 404 errors” in Webmaster Tools. If you want to see exactly what HTTP responses are being returned by your server, I’m a big fan of the httpsfox plugin for Firefox–it will show you not only the final HTTP code, but each hop along the way, if there are multiple redirects.
Conclusion
There’s a million ways to shoot yourself in the foot when it comes to search optimization. With a little luck, some of you have some juicy horror stories to share in the comments!
SEO consultant, specializing in organic search, site audits, Panda optimization, and penalty recovery. Founder of Visual Itineraries travel planning website.
I’ve seen the robots.txt for the staging site (which excluded everything) get copied over to the live site (which then became deindexed). I’ve also seen the live site’s robots.txt get copied over to the staging site when a data refresh of the staging site was done, resulting in the staging site being indexed. I used https://polepositionweb.com/roi/codemonitor/index.php to monitor the robots.txt on the live and all staging versions of the site to help catch these changes right away.
If the primary site is www and the non-www does correctly redirect, the following search can help turn up subdomains you didn’t know about:
site:example.com -site:www.example.com
Don’t order cake when you see your bounce rate drop to one or two percent. In an incognito window, check the source code to see if you’ve got two instances of analytics code running. I learned this one the hard way on a WordPress site. When I was logged in as admin, the analytics code via a plugin was being suppressed, so when I viewed the source, I was only seeing the analytics code I had put in one of the theme files, and not the second one from the plugin.
Thanks for the robots.txt monitoring tip Keri–I hadn’t seen that before. And the 2x Analytics one…I’ve seen client sites that have had that problem but hadn’t noticed the bounce rate effect.
Great article. Definitely a few take away points. On the “Site of Many Flavours” section I would also include not dealing with a wildcard DNS records properly i.e. the site handle requests for *.mysite.com and doesn’t redirect to the www version when there is no legitimate sub domain. This will end up creating an infinite number of duplicate versions.
Thanks Chris–good tip on the DNS wildcards issue. I’ve tended to avoid wildcard DNS and instead, manually set up each subdomain. Of course, there are some business models (like cheap subdomain hosting e.g. tumblr, blogspot) where you really need to go the wildcard route.